Sparse Indexesとは
- DynamoDBのデータ抽出アプローチのテクニックの1つ
- 特定Itemにしか設定していない項目にGSIを含めることでプライマリーキー、ソートキー以外のキーでデータ抽出を容易に
- 以下の悩みを解決(プライマリーキー、ソートキー以外のキーでデータ抽出)
- scanだと高コスト、キーで検索しても高コスト、フィルターだとキー検索とコスト一緒
サンプル: gameから最優秀賞を取得
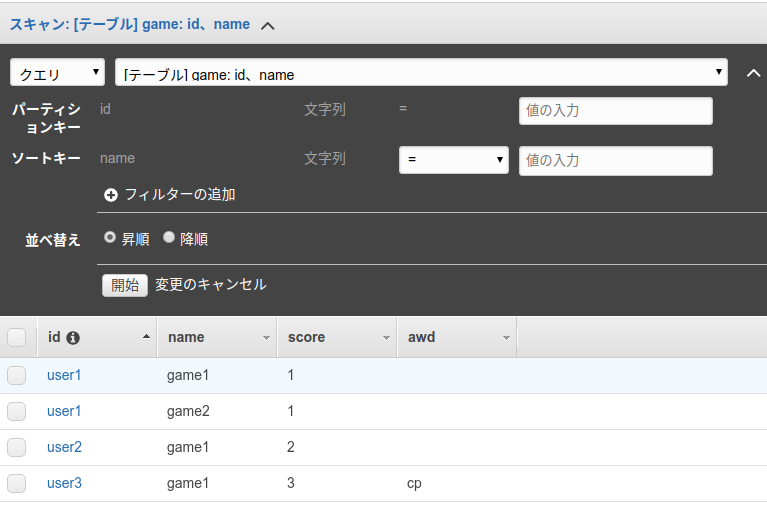
初期テーブル
- game単位で最優秀スコアのデータを取得したい
- scoreの最優秀をawdという項目を用意。対象以外は項目を設定しない
awdを含めたグローバルセカンダリインデックスを作成

GSIを検索
- 最優秀賞が設定されている項目が少ないため、VIEWが出来た時点で絞り込まれている
- scanしても低コスト!←今回の一番のポイント
aws dynamodb scan --table-name game --index-name name-awd-index
{
"Count": 1,
"Items": [
{
"score": {
"S": "3"
},
"id": {
"S": "user3"
},
"awd": {
"S": "cp"
},
"name": {
"S": "game1"
}
}
],
"ScannedCount": 1,
"ConsumedCapacity": null
}